导致mysql数据库CPU高的常见原因
占用CPU过高,可以做如下考虑
- 一般来讲,排除高并发的因素,还是要找到导致你CPU过高的哪几条在执行的SQL,show processlist语句,查找负荷最重的SQL语句,优化该SQL,比如适当建立某字段的索引;
- 打开慢查询日志,将那些执行时间过长且占用资源过多的SQL拿来进行explain分析,导致CPU过高,多数是GroupBy、OrderBy排序问题所导致,然后慢慢进行优化改进。比如优化insert语句、优化group by语句、优化order by语句、优化join语句等等;
- 考虑定时优化文件及索引;
- 定期分析表,使用optimize table;
- 优化数据库对象;
- 考虑是否是锁问题;
- 调整一些MySQL Server参数,比如key_buffer_size、table_cache、innodb_buffer_pool_size、innodb_log_file_size等等;
- 如果数据量过大,可以考虑使用MySQL集群或者搭建高可用环境。
- 可能由于内存(泄露)导致数据库CPU高
- 在多用户高并发的情况下,任何系统都会hold不住的,所以,使用缓存是必须的,使用memcached或者redis缓存都可以;
- 看看tmp_table_size大小是否偏小,如果允许,适当的增大一点;
- 如果max_heap_table_size配置的过小,增大一点;
- mysql的sql语句睡眠连接超时时间设置问题(wait_timeout)
- 使用show processlist查看mysql连接数,看看是否超过了mysql设置的连接数
一般定位步骤
- 首先看看内存 free –m
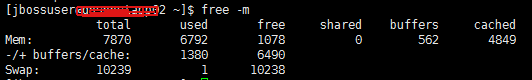
目前看没有问题,1G的空闲
- 好了,用我们的必杀技,top看看资源消耗
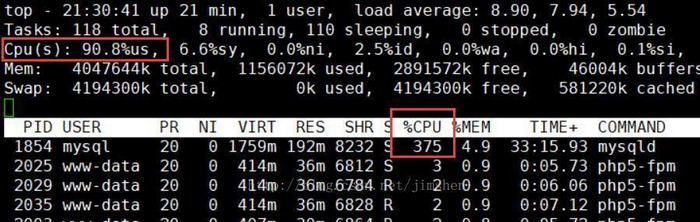
可以看到服务器负载很高,mysql CPU使用已达到接近400%,基本可以看出mysql是可以进行优化的
- 进入mysql,执行show full processlist;

这里我们要看的其实就2点:线程数和慢sql
现在我们看到线程就5个,可以先排除线程的问题了。
那我们接下来就是来看看慢sql了
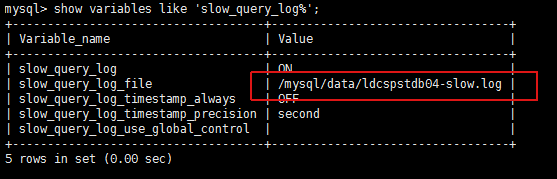
- 首先我们先执行show variables like ‘slow_query_log%’;来查看慢日志的路径
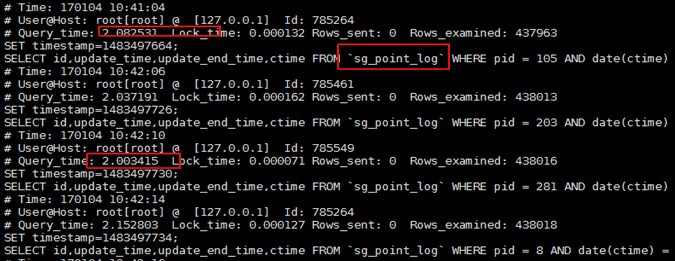
- 我们排查该文件中的慢sql,这里我们看出来了是查询语句直接耗时2秒,explain 该sql发现耗时超过10S
数据库注意事项
1、重要的sql必须被索引
1)select、update、delete语句的where条件列;
2)order by、group by、distinct字段
2、mysql索引的限制
1)mysql目前不支持函数索引
2)使用不等于(!=或者<>)的时候,mysql无法使用索引
3)过滤字段使用单行函数 (如 abs (column)) 后, MYSQL无法使用索引。
4) join语句中join条件字段类型不一致的时候MYSQL 无法使用索引
5)使用 LIKE 操作的时候如果条件以通配符开始 (如 ‘%abc…’)时, MYSQL无法使用索引。
6)使用非等值查询的时候, MYSQL 无法使用 Hash 索引。
7)BLOB 和 TEXT 类型的列只能创建前缀索引
3、mysql常见sql规范
1)SQL语句尽可能简单 大SQL语句尽可能拆成小SQL语句,MySQL对复杂SQL支持不好。
2)事务要简单,整个事务的时间长度不要太长,SQL结束后及时提交。
3)限制单个事务所操作的数据集大小,不能超过 10000 条记录
4)禁止使用触发器、函数、存储过程。
5)降低业务耦合度,为scale out、sharding留有余地
6)避免在数据库中进行数学运算(数据库不擅长数学运算和逻辑判断)
7)避免使用select *,需要查询哪几个字段就select这几个字段,避免buffer pool被无用数据填充。
8)条件中使用到OR的SQL语句必须改写成用IN()(OR的效率比IN低很多)
9)IN()里面的数据个数建议控制在 500 以内,可以用exist代替in,exist在某些场景比in效率高,尽量不使用not in。
10)limit分页注意效率。 limit越大,效率越低。可以改写limit,例如:
select id from test limit 10000,10 可以改写为 select id from test where id > 10000 limit 10
11)当只要一行数据时使用LIMIT 1 。
12)获取大量数据时,建议分批次获取数据,每次获取数据少于 10000 条,结果集应小于 1M
13)避免使用大表做 JOIN,使用group by分组、自动排序
14)SQL语句禁止出现隐式转换,例如:select id from test where id=’1’,其中 id 列为 int 等数字
类型。
15)在SQL中,尽量不使用like,且禁止使用前缀是%的like匹配。
16)合理选择union all与union
17)禁止在OLTP类型系统中使用没有where条件的查询。
18)使用 prepared statement 语句,只传参数,比传递 SQL 语句更高效;一次解析,多次使用;降低SQL注入概率。
19)禁止使用 order by rand().
20)禁止单条 SQL 语句同时更新多个表。
21)不在业务高峰期批量更新或查询数据库,避免在业务高峰期alter表。
22)禁止在主库上执行 sum,count 等复杂的统计分析语句,可以使用从库来执行。